

This post is the first of the series of estimation.
You need the following knowledge to understand maximum likelihood estimation and everything else based on it. This is the bottom line.
I assume you already have some basic knowledge of probability theory, e.g. the definition of probability, so we’ll skip that part.
We are reviewing conditional probability, the Total probability theorem, the Bayesian Theorem, Bernoulli distribution, binomial distribution, multinomial distribution, normal distribution, the likelihood function, logarithm rules, and derivative rules
The Venn diagrams are useful for understanding probabilities.


Conditional probability
Given two events A and B from the sigma-field of a probability space with 

Sometimes 

The conditional probability defines a new universe.


In general, it cannot be assumed that 
Events A and B are defined to be statistically independent if

Note that mutually exclusive events (or disjoint events) must be dependent events, but non-mutually exclusive events (or overlapping events) could be independent.
Total probability theorem
The events 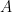

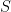



Bayesian Theorem

Bayesian Theorem can be regarded as a rule to update an initial probability 

Click here for an Intuitive explanation of Bayesian Theorem.
Bernoulli distribution
The Bernoulli distribution, named after Swiss scientist Jacob Bernoulli, is the probability distribution of a random variable which takes the value 1 with success probability of 

If X is a random variable with this distribution, we have:

![\mathbb{E}[X] = Pr(X=1) \cdot 1 + Pr(X=0) \cdot 0 = p \cdot 1 + q\cdot 0 = p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+Pr%28X%3D1%29+%5Ccdot+1+%2B+Pr%28X%3D0%29+%5Ccdot+0+%3D+p+%5Ccdot+1+%2B+q%5Ccdot+0+%3D+p&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
Have some fun with the following R code.
#draw two numbers from the Bernoulli distribution with p=0.5
p<-0.5
set.seed(1232)
if( runif(1) < p ) {y<-1} else {y<-0}
y
set.seed(2222)
if( runif(1) < p ) {y<-1} else {y<-0}
y
Binomial distribution
The binomial distribution with parameters n and p is the discrete probability distribution of the number of successes in a sequence of n independent yes/no experiments, each of which yields success with probability

for k = 0, 1, 2, …, n, where

Suppose a biased coin comes up heads with probability 0.3 when tossed. What is the probability of achieving 0, 1,…, 6 heads after six tosses?






If X ~ B(n, p), that is, X is a binomially distributed random variable, n being the total number of experiments and p the probability of each experiment yielding a successful result, then the expected value of X is:
![\mathbb{E}[X] = np](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+np+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
# random generation for the binomial distribution with size=10 and prob=0.5 rbinom(n=2, siz=10, prob=0.5)
Multinomial distribution
The multinomial distribution is a generalization of the binomial distribution. For n independent trials each of which leads to a success for exactly one of k categories, with each category having a given fixed success probability, the multinomial distribution gives the probability of any particular combination of numbers of successes for the various categories.

when 

The expected number of times the outcome i was observed over n trials is
![\mathbb{E}[X_i] = n p_i](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_i%5D+%3D+n+p_i&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
# random generation for the multinomial distribution with size=10 and prob=0.5 rmultinom(n=2, size=10, prob=c(0.1,0.3,0.6))
Normal distribution
The normal (or Gaussian) distribution is a very common continuous probability distribution. Normal distributions are important in statistics and are often used in the natural and social sciences to represent real-valued random variables whose distributions are not known.
The probability density of the normal distribution is:

![\mathbb{E}[X]=\mu](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D%3D%5Cmu&bg=%23ffffff&fg=%23000000&s=0&c=20201002)

If 

# random generation for the normal distribution with mean=10 and variance=9 rnorm(n=10, mean=10, sd=3)
Likelihood function
A likelihood function (often simply the likelihood) is a function of the parameters of a statistical model. Likelihood functions play a key role in statistical inference, especially methods of estimating a parameter from a set of statistics.
“Probability” is used when describing a function of the outcome given a fixed parameter value.
“Likelihood” is used when describing a function of a parameter given an outcome.
The likelihood of a set of parameter values, 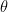

Logarithm rules
When b raised to the power of y is equal x: 
Natural logarithm is a logarithm to the base e:
Logarithm product rule:
Logarithm quotient rule:
Logarithm power rule:





Derivative rules

Power Rule:
Chain Rule:






The first diagram does not show.
LikeLike
Now it’s fixed. Thanks!
LikeLike